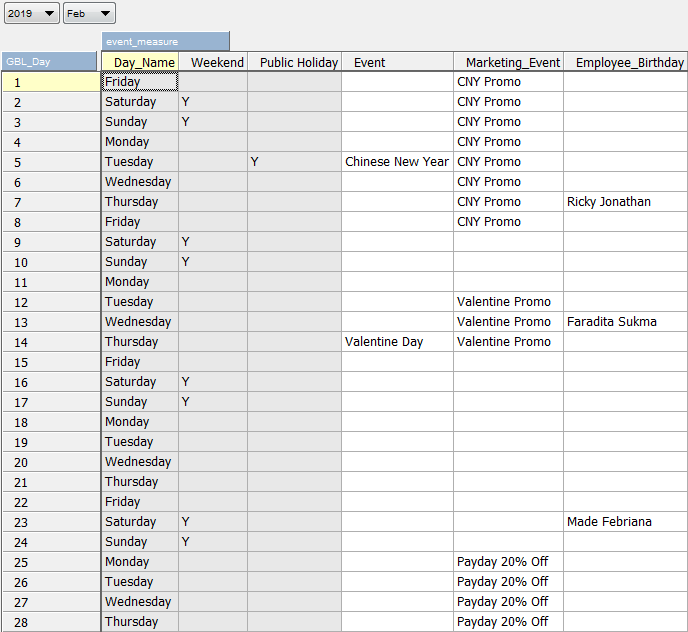
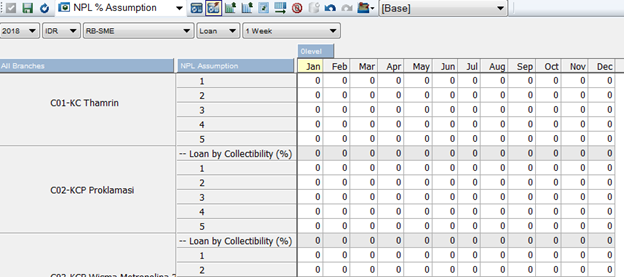
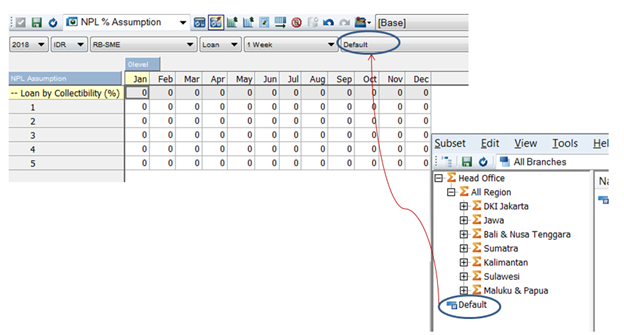
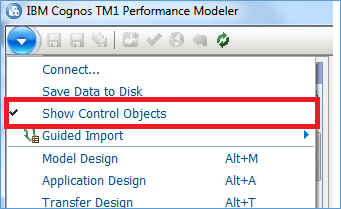
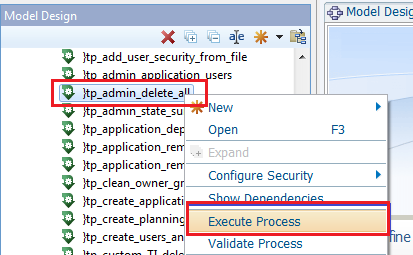
Did you ever contact customer service and fed up with them because it seems they do not understand your question but still answer politely and not even try to understand your problems.
Wasting time, isn’t it?
Customer services act like robots because they are being a textbook. Answer any question just based on their textbook. Or maybe only for difficult questions that they don’t understand. They choose to be a textbook rather than say nothing or apologize because they don’t have answer to your question yet.
How if the human customer service skill combine with the robot customer service such as ChatGPT? Will it be better?
ChatGPT is a generative Artificial Intelligence in form of chatbot. It has capability to provide answers to any questions depend on the data and information it can read.
Human customer service can ask ChatGPT for help when they don’t have any answer on their mind to customer’s question. So, when a customer asks for a question, they can also open AI chatbot to find solution. At least they can give make sense answer.
This solution can be used for IT technical supports as well, where usually the job is more difficult than general customer service.
IT technical support will need investigation to understand problems. So, it will take some times to collect information from their users and after that find solution to fix the problem. In general, it will need basic IT knowledge to do the job and especially on the IT domain specific to what they support. They will need to be trained to master the skill and also some experiences.
A company that its business provides technical support in software administrative to other companies, decided to adopt an earlier version of OpenAI’s ChatGPT to improve the performance of their tech sup agents that based primarily in the Philippine, but also in US and other countries. Of course they use their own data to train the machine so it can provide correct information to help the tech sup agents.
As tech sup of certain software, someone has to understand how the software works and how to solve problems. Their skill should improve time to time. But, in reality this job is not that easy, especially for beginners. Seems it’s stressful job and there’s high turnover causing the company had to train new staff again and again.
By implementing chatbot, such as Chatgpt, they can overcome the situation. The staff could improve their performance better, less stress, and customers also happy with their service.
That a sample where AI implementation is not always replacing human workers but help human workers do their job.
We are, human, much smarter than robots, so there will always jobs for us. (VRGultom)